YOLOv3 custom dataset을 가지고 훈련을 진행 해보도록 하겠다.
환경은 우분투 20.04 LTS 에서 진행 하도록 하겠다. 사전에 설치해야할 항목들은
1. Nvidia-driver
2. CUDA, CUDNN
3. OpenCV
4. Darknet
이렇게 준비가 되어 있어야 한다.
준비가 완료 되었으면 custom dataset을 준비해 준다. 필자는 YOLO_mark를 이용해 준비를 해둔 상태이므로 이부분은
본 게시물에서는 설명하지 않도록 하겠다. 준비가 되었으면 다음 단계로 진행한다.
Darknet 폴더로 이동해 custom_yolov3 폴더를 만들어준다. 아래의 사진처럼 5개의 파일이 있어야 한다.

준비해야할 부분을 하나씩 보도록 하겠다.
1. img 폴더
폴더 내에는 yolo_mark를 이용해 annotation한 이미지와 txt파일이 있는 곳이다.
학습 이미지 와 annotation 파일은 같은 폴더 내에 있어야 한다. 이때 사진 과 annotation의 파일명은 같아야 한다.
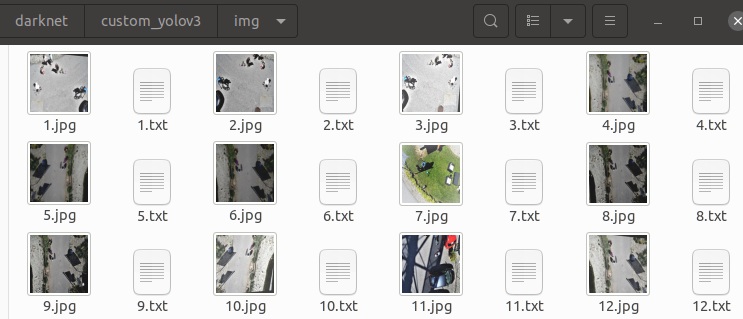
여기서 txt 파일은 train, validation의 경로가 아닌 이미지상 label이 저장되어 있는 파일이다.
파일의 구성은 다음과 같이 구성이 된다.
<class number> <x> <y> <width> <height>

2. custom.data
학습을 진행 하기 위한 내용들의 경로가 들어있는 파일이다. 구성은 아래의 사진과 같이 되어있다.
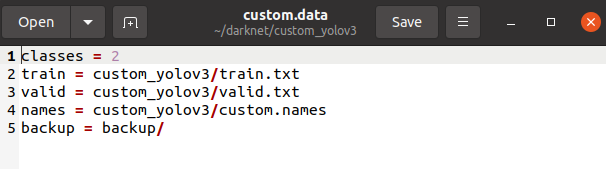
classes 에는 본인이 학습 시키고 싶은 class의 갯수를 적어 주면 된다.
train, valid는 이미지의 경로가 저장되어 있는데 여기서 validation data set이 필요없으면 굳이 지정안해줘도 된다.
names는 class의 이름이 저장되어 있는 파일이다.
backup은 학습시 iteration을 거치면서 train.log, weight 또는 결과가 저장이 되는 경로이다.
3.custom.names
class의 이름이 저장되어 있는 파일이다. class가 여러개 일때 line by line으로 구분한다.
여기서 custom.data의 classes와 갯수가 같아야 한다.

4. train.txt , valid.txt
훈련을 하기위해 train, validation의 이미지의 경로가 저장되어 있는 파일이다.
이미지의 경로만 들어가야 한다. train, validation set으로 나누는 방법은 차후에 올리도록 하겠다.

5. yolov3.cfg
여기서 부터가 모델을 수정하는 부분이다. 수정해야할 부분이 많음으로 주의깊게 수정해야 한다.

model의 parameter구성 단계이다.
| Parameter | Value | Description |
| batch | 64 | 모델 학습 중 parameter를 업데이트할 때 사용할 데이터 개수 클수록 정확도 향상 (CUDA out of memory 발생 시 2의 배수 로 줄이면서 조절) |
| subdivisions | 16 | 배치 사이즈인 64를 얼마나 쪼개서 학습을 할건지에 대한 설정 값 작을수록 정확도 향상 (CUDA out of memory 발생 시 2의 배수 로 늘려가면서 조절) |
| width, height | 416 | 32의 배수로 늘리거나 줄여가면서 학습진행 (커지면 정확도가 좋아질수 있으나 GPU 사용이 많아져서 CUDA out of memory 발생) |
| channels | 3 | 이미지의 채널 이다. 보통 RGB 이미지 파일을 사용하므로 3개이다. |
| momentum | 0.9 | 경사하강법의 최적화 알고리즘 중 gradient를 보정하는 설정값 |
| decay | 0.0005 | overfitting을 방지하기위해 weight가 너무 큰 값을 가지지 않도록 Loss function에 Weight가 커질경우에 대한 패널티 항목이다. |
| angle | 0 | augmentation에 관련된 값 이미지에 랜덤으로 -, + 몇 도 돌릴 것인지에 대한 설정 값 |
| saturation | 1.5 | augmentation에 관련된 값 이미지에 랜덤으로 이미지의 채도를 변환 하는 설정값 |
| exposure | 1.5 | augmentation에 관련된 값 이미지에 랜덤으로 이미지의 노출(밝기)를 변환 하는 설정값 |
| hue | .1 | augmentation에 관련된 값 이미지에 랜덤으로 이미지의 색상을 변환하는 설정값 |
| learning_rate | 0.0001 | 초기 학습률 multi-gpu 사용 시 학습률을 0.001 / gpu 수 만큼 조절하기도 한다. |
| burn_in | 1000 | 해당 training iteration동안 learning_rate를 일정한 수치만큼 높인다. multi-gpu 사용 시 1000 * gpu 수 만큼 조절함 |
| max_batches | 4200 | iteration을 돌건지 설정하는 값 max_batches=class 수 * 2000 + 200으로 설정 [ex : 1 class 의 경우 (1 * 2000) + 200 = 2200] |
| policy | steps | training시에 learning_rate를 어떤 방식으로 조정할지 설정값 (random or steps) |
| steps | 3200,3600 | max_batches 사이즈에 80%, 90%설정(-200 제외) [max_batches=2200 이면 2000의 80%=1600, 90%=1800 |
| scales | .1, .1 | steps에 따라 learning_rate에 해당 수치만큼 곱한다. |
여기까지 초기 parameter설정이고 다음으로 network를 수정해야 한다.
classes 와 filters의 값들을 바꿔줘야 한다. yolov3.cfg 파일에서 'yolo'를 검색한다.

총 세군데를 다음과 같이 변경을 해줘야 한다.
classes = class 갯수
filters = (class 개수 + 5) *3
anchors는 아래의 명령어를 입력해 나오는 값으로 변경을 해준다.
width와 height는 cfg 의 width, height와 같게 맞춰주면 된다
$ ./darknet detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416
6. darknet53.conv.74
darknet에서 제공하는 pretrain 모델을 이용하면 좀 더 빠르고 정확한 학습을 진행할 수 있다. 아래의 코드를 입력해 다운 받을수 있다.
$ wget https://pjreddie.com/media/files/darknet53.conv.74이제 YOLOV3를 custom dataset을 이용해 학습을 할 준비가 되었다.
아래의 명령을 입력해 학습을 시작한다.
$ ./darknet detector train .data파일위치 .cfg파일위치 weight파일위치 -map | tee backup/train.log학습중에 지표들을 보고 싶으면 아래의 명령어를 입력한다.
순서대로 iteration : loss(iou), loss(classify), learning rate, iteration time, 훈련 이미지 수 가 출력이 된다.
$ grep "avg" backup/train.log학습이 종료되면 다음과 같이 그래프가 저장이 된어 학습결과를 확인할수 있다.

훈련 결과를 확인 하기 위해 다음과 같이 입력하면 훈련결과를 확인할수 있다.
$ ./darknet detector test custom_yolov3/custom.data custom_yolov3/yolov3.cfg backup/yolov3_best.weights 사진.jpg
$ ./darknet detector demo custom_yolov3/custom.data custom_yolov3/yolov3.cfg backup/yolov3_best.weights -ext_output 동영상.mp4
$ ./darknet detector demo custom_yolov3/custom.data custom_yolov3/yolov3.cfg backup/yolov3_best.weights -c 0 (웹캠)
Reference
https://keyog.tistory.com/6?category=879585
Yolo v3 custom 데이터 훈련하기
Yolo v3 설치하기 2020/04/17 - [Computer Vision/Object detection] - Yolo v3 설치하기 Yolo v3 설치하기 object detection 분야에서 유명한 yolo의 설치법 및 사용법을 작성한다. 모든 딥러닝 라이브러리가 마찬가지겠지
keyog.tistory.com
https://eehoeskrap.tistory.com/370#2.2-cfg-%ED%8C%8C%EC%9D%BC-%EC%84%A4%EC%A0%95
[Object Detection] darknet custom 학습하기
darknet 학습을 위해 이전에 처리해야할 과정들은 다음 포스팅을 참고 [Object Detection] darknet custom 학습 준비하기 https://eehoeskrap.tistory.com/367 [Object Detection] Darknet 학습 준비하기 환경 Ubuntu 16.04 GeForce R
eehoeskrap.tistory.com
[Perception Open Source] YOLO
소개 YOLO(You Only Look Once)는 Object Detection을 구현한 오픈소스입니다. 최근 YOLO, SSD, Mask RCNN, RetinaNet 등의 다양한 Object Detection 알고리즘들을 개발됐는데, YOLO는 기존 모델들 보다 더 높은 정확도를 추
hnsuk.tistory.com
https://pjreddie.com/darknet/yolo/
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
정확한 정보 전달보단 공부 겸 기록에 초점을 둔 글입니다. 틀린 내용이 있을 수 있습니다.
틀린 내용이나 다른 문제가 있으면 댓글 남겨주시거나 또는 이메일로 보내주시면
감사하겠습니다.
'Object Detection > YOLO' 카테고리의 다른 글
| YOLOv6 custom Train (0) | 2024.01.29 |
|---|---|
| YOLOv5 custom Train (0) | 2024.01.28 |
| YOLOv4 custom Train (1) | 2024.01.27 |
| [Ubuntu 20.04 LTS] Darknet 설치 (0) | 2024.01.24 |
| YOLO_mark 사용법 (0) | 2024.01.19 |